讓靜態部落格對 AI Agent 更友善:Is It Agent Ready? 實測與改造紀錄
最近 Cloudflare 推出了一個有趣的小工具 Is It Agent Ready?,用來評估你的網站對 AI Agent 的友善程度。
剛好拿自己的部落格去掃了一下,分數 8 分 Not Ready,真慘。 看了一輪檢查項目,覺得有些確實值得做,就順手做了兩輪改造,最後把分數推到 58 分 Level 4 Agent-Integrated,也順便把「哪些該做、哪些不必做」的判斷整理起來。
什麼是 isitagentready.com?
這是 Cloudflare 維運的一個靜態檢查工具,給它一個網址,就會從幾個面向評估你的網站準備好「被 AI Agent 使用」了沒。這裡的 Agent 指的不只是傳統爬蟲,還包括會代替使用者瀏覽網站、呼叫 API、做決策的新一代 AI 應用。
評分分四大類(另加一個 Commerce 類別為選配,不計分):
- Discoverability 可發現性:sitemap、robots.txt、Link response headers
- Content 內容:是否支援 Markdown Negotiation,也就是當 Agent 要求 markdown 格式時,能否直接給它乾淨的 markdown 而不是 HTML
- Bot Access Control 機器人存取控制:robots.txt 裡是否明確聲明 AI 爬蟲規則、是否有 Content Signals、是否實作 Web Bot Auth
- API, Auth, MCP & Skill Discovery:API Catalog、OAuth/OIDC、MCP Server Card、Agent Skills index、WebMCP 等
每個檢查項目都有明確的 Goal、Issue、How to implement,還附上對應 RFC 和實作參考,整體體驗蠻不錯的。
初始分數:8 分
第一次掃描結果很慘:
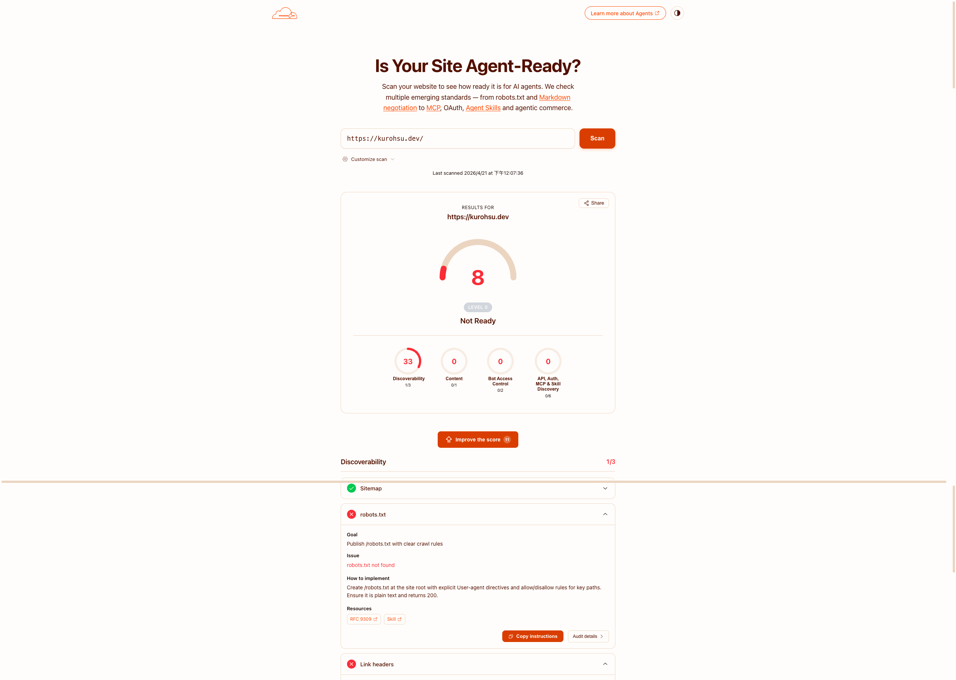
- Discoverability:1/3,只有 sitemap 過關
- Content:0/1
- Bot Access Control:0/2
- API, Auth, MCP & Skill Discovery:0/6
VitePress 本身有內建 sitemap,這是唯一白撿的分數,其他全軍覆沒,笑死。
第一輪改造:robots.txt 與 Link headers
這兩項是成本最低的全壘打,做完分數從 8 直接跳到 42(Level 2 Bot-Aware)。
robots.txt
在 docs/public/robots.txt 建立一份同時滿足三個檢查項目的 robots.txt:
User-agent: *
Allow: /
# AI crawlers 明確允許(技術筆記希望被 AI 搜尋發現)
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
# Content Signals (https://contentsignals.org)
# search=yes: 允許搜尋索引
# ai-input=yes: 允許作為 AI 即時回答的輸入
# ai-train=no: 不允許作為訓練資料
Content-Signal: search=yes, ai-input=yes, ai-train=no
Sitemap: https://kurohsu.dev/sitemap.xml這邊有幾個設計值得說明:
第一,對 AI 爬蟲我選擇 Allow。技術筆記本來就是寫給人看的,被 AI 在回答時引用到對流量反而是加分。
第二,Content-Signal 是 Cloudflare 在 2025 年提出、夾在 robots.txt 裡的新指令(詳見 Content Signals Policy 與 contentsignals.org)。在它出現之前,robots.txt 只能用 Allow / Disallow 粗略表達「能不能爬」,但「爬了之後能拿去做什麼」一直是模糊地帶。Content Signals 把內容用途拆成三個獨立訊號,每一個都用 yes 或 no 表達:
search:允許被用在傳統搜尋索引,也就是回連結跟短摘要的那種搜尋結果,不包含 AI 生成的摘要ai-input:允許被 LLM 在即時回答時當作引用來源,典型情境是 RAG(retrieval-augmented generation)ai-train:允許被拿去訓練或微調 AI 模型
寫法是在 User-agent 區塊裡加一行 Content-Signal: ...,多個訊號用逗號分隔。沒列到的訊號代表「不表達意見」,而不是預設反對。
我的選擇是 search=yes, ai-input=yes, ai-train=no,允許被搜尋與即時引用,但不允許當訓練素材。這裡順帶澄清一個我自己也差點搞錯的細節:Cloudflare 託管 robots.txt 的預設值其實是 search=yes, ai-train=no,並不會代替使用者自動聲明 ai-input,官方理由是無法預判客戶偏好,不想替人決定。
不過有一點要先講清楚:Content Signals 只是聲明,不是技術強制。它依賴各家 AI 爬蟲自主遵守,本質上跟 robots.txt 的 Disallow 是同樣道理。這不是防火牆,比較像是把意願攤在陽光下,讓合規的 bot 有所依據,也讓後續的法律或政策討論有個可以指的對象。
第三,Sitemap: 指令放最後,讓爬蟲不用自己猜 sitemap 在哪,雖然傳統但很實用。
Link response headers
RFC 8288 定義的 Link header,目的是讓 Agent 不需要解析 HTML 就能找到站台的重要資源。
這個站架在 Vercel 上,所以在 vercel.json 加:
{
"headers": [
{
"source": "/(.*)",
"headers": [
{
"key": "Link",
"value": "</sitemap.xml>; rel=\"sitemap\", </feed.xml>; rel=\"alternate\"; type=\"application/rss+xml\", </atom.xml>; rel=\"alternate\"; type=\"application/atom+xml\", </feed.json>; rel=\"alternate\"; type=\"application/feed+json\""
}
]
}
]
}一條 Link header 指向 sitemap、RSS、Atom、JSON Feed,這樣 Agent 拿到首頁 response 的當下就能找到所有訂閱管道。
做完這兩項,重新掃描:42 分。Discoverability 3/3,Bot Access Control 2/3(Web Bot Auth 是選配的加密簽章驗證,對個人站台來說過度了),短時間內能撿的分都撿起來了。
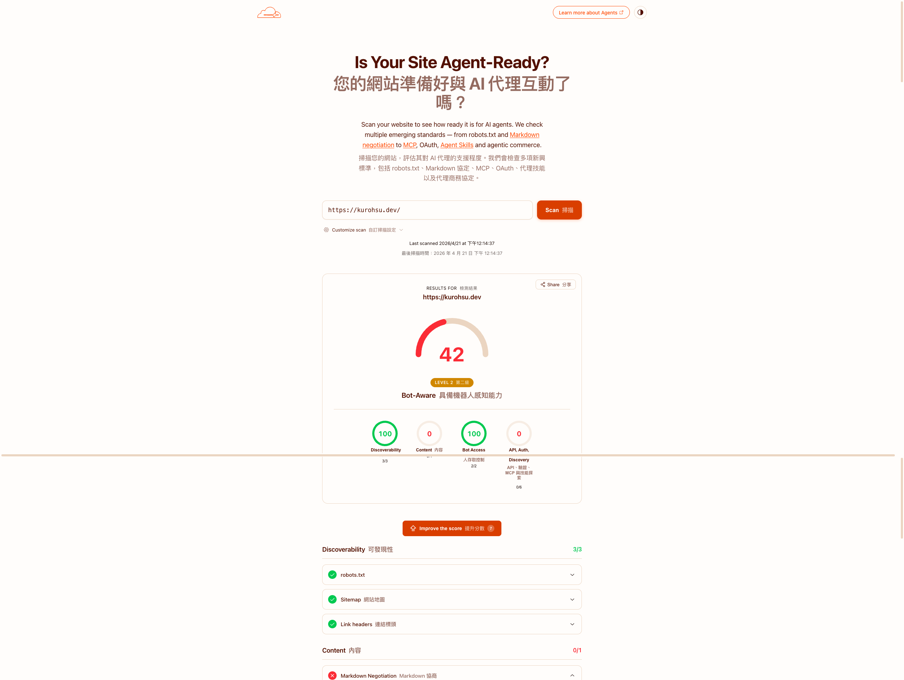
第二輪改造:Markdown Negotiation 與 Agent Skills
第一輪處理掉了「只需要加檔案就能解」的項目。接下來要拉分,只剩下兩個實際對 Agent 有用的:Markdown Negotiation(Content 類)與 Agent Skills index(API 類)。
Markdown Negotiation
Agent 跟瀏覽器的需求不一樣。瀏覽器要 HTML 加樣式,Agent 只想要乾淨的文本。Markdown Negotiation 的做法是,同一個 URL 依據 request 的 Accept header 回傳不同格式:瀏覽器給 HTML,Agent 要求 text/markdown 就給 markdown。
我的做法分兩步。
第一步,在 VitePress buildEnd hook 加一個產生器,把每篇文章的原始 .md(去掉 frontmatter)輸出到 dist 對應的扁平路徑:
// scripts/generateMarkdownFiles.ts
export async function generateMarkdownFiles(config: SiteConfig) {
const outDir = config.outDir
const docsDir = path.resolve(config.srcDir)
for (const category of ['notes', 'learn', 'misc']) {
const files = walkMarkdownFiles(path.join(docsDir, category))
for (const absPath of files) {
const raw = fs.readFileSync(absPath, 'utf-8')
const { data: frontmatter, content } = matter(raw)
if (frontmatter.draft) continue
const slug = path.basename(absPath).replace(/\.md$/, '')
const outPath = path.join(outDir, category, `${slug}.md`)
fs.mkdirSync(path.dirname(outPath), { recursive: true })
fs.writeFileSync(outPath, content.trimStart(), 'utf-8')
}
}
// ... 還會產生 index.md 與 about.md
}產出後,docs/.vitepress/dist/ 底下就會同時有 notes/article.html 和 notes/article.md 兩個檔案。
第二步,在 vercel.json 加條件式 rewrite 和 Content-Type override:
{
"rewrites": [
{
"source": "/:category(notes|learn|misc)/:slug.html",
"has": [
{ "type": "header", "key": "accept", "value": ".*text/markdown.*" }
],
"destination": "/:category/:slug.md"
}
],
"headers": [
{
"source": "/:category(notes|learn|misc)/:slug.html",
"has": [
{ "type": "header", "key": "accept", "value": ".*text/markdown.*" }
],
"headers": [
{ "key": "Content-Type", "value": "text/markdown; charset=utf-8" },
{ "key": "Vary", "value": "Accept" }
]
}
]
}重點是 has 條件,只有當 request header 含 Accept: text/markdown 時才會觸發 rewrite,瀏覽器的 Accept 不包含這個值,日常瀏覽完全不受影響。
Vary: Accept 則是告訴 CDN 要依照 Accept 分別快取不同版本,避免把 markdown 版本回給瀏覽器,或反過來。
Agent Skills index
這是 Cloudflare 推動中的新興 discovery 規範(目前 RFC 還在 v0.2.0,規格仍在演進),位置在 /.well-known/agent-skills/index.json,用來讓站台「告訴 Agent 我這裡能做什麼」。
對純內容站來說,合理的 skill 有兩個:
read-article-as-markdown:Agent 可以透過 Accept negotiation 拿到任何文章的 markdowndiscover-articles:Agent 可以透過 sitemap、RSS、tag 頁等方式列出文章
我在 docs/public/.well-known/agent-skills/ 建了兩個 skill 描述檔(markdown 格式),再寫一個 build script 讀取這些檔案、計算 sha256,輸出 index.json:
// scripts/generateAgentSkills.ts
const index = {
$schema: 'https://schemas.agentskills.io/discovery/0.2.0/schema.json',
skills: SKILLS.map(skill => ({
name: skill.name,
type: 'skill-md',
description: skill.description,
url: `${siteUrl}/${skill.path}`,
digest: sha256Digest(path.join(outDir, skill.path))
}))
}Skill 描述檔用 markdown 寫,方便人類也能讀;digest 則提供完整性比對的基礎,讓消費端有能力驗證檔案沒被動過手腳。不過這條信任鏈成不成立,終究還是要看 Agent 那端是否真的實作了驗證流程。
為什麼剩下的五項我選擇不做
檢查報告還剩五個紅燈:API Catalog、OAuth/OIDC Discovery、OAuth Protected Resource、MCP Server Card、WebMCP。 這些我選擇暫時不實作,硬湊只會變成 cargo-cult,分數是好看了,但對個人部落格來說毫無實際意義,甚至可能因為多了沒必要的 endpoint 反而誤導 Agent。
API Catalog (RFC 9727) 要求列出站上的 API 加 OpenAPI spec 加 health endpoint。純靜態部落格根本沒有 API,把 feed.json 當 API 硬塞是在誤導 Agent。
OAuth/OIDC Discovery 需要你有 OAuth server 或 OpenID provider。這個站零認證,發布空的 metadata 會告訴 Agent「這裡可以拿 token」然後什麼都沒有,反而破壞信任。
OAuth Protected Resource 同上,要有「被保護的資源」才有意義。
MCP Server Card 是 MCP server 的名片,前提是你真的跑了一個 MCP server。只貼 card 沒有對應 endpoint,Agent 連過來就 404。這倒是一個有點意思的延伸題目,像是做一個「用 MCP 協議查部落格內容」的 server,不過那是另一個獨立專案了,不是加個檔案能解決的事。
WebMCP 是目前唯一對內容站可能有意義的,但現階段還在 Chrome 早期預覽計畫(Early Preview Program)階段,要報名才能拿到文件和 demo,spec 也還在變動。靜態網站為了這件事特別載入 client runtime script 成本不對等,等跨瀏覽器都支援再來做 CP 值會好很多。(後來還是花時間補做了一輪,研究筆記跟 demo 寫在 初試 WebMCP 那篇。)
最終分數與一些觀察
兩輪改造結束,分數從 8 推到 58 分 Level 4 Agent-Integrated:
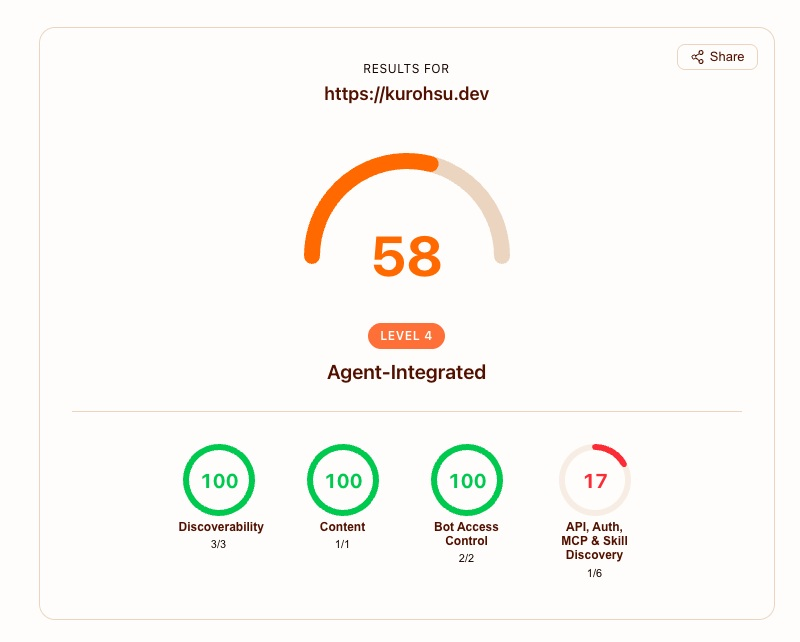
Discoverability、Content、Bot Access Control 三個類別都是滿分,API / Auth / MCP & Skill Discovery 拿到 1/6(Agent Skills index 過關)。對一個純內容靜態部落格來說已經接近上限了,剩下的 40 分是給有 API、有認證、有 MCP 基礎設施的站台準備的。
有幾個觀察值得記錄:
第一,「分數」不是目的。isitagentready.com 的檢查清單本質上是一份 best-practices,不同類型的站台適用的項目也不一樣。個人部落格硬追到 100 分,代表你在發布一堆假的 endpoint,對真正的 Agent 反而是雜訊。
第二,Markdown Negotiation 是最實用的一項。當 AI Agent 幫使用者讀你的文章時,省掉 HTML 解析這一層可以大幅降低雜訊,這個改動對內容可讀性最有感,分數反而是順帶的。
第三,Cloudflare 這套檢查會順帶把 robots.txt 的 AI 爬蟲規則、Content Signals 這些新規範一次推給你。就算不打算做 MCP,前半段的 Discoverability 跟 Bot Access Control 還是很值得跑一次,花不到十分鐘就能補完。
第四點是個保留:這篇目前都停在「能力層」,也就是「站台現在有能力被乾淨地抓、被 well-known 路徑發現」。但實際上到底有沒有 Agent 真的送 Accept: text/markdown、/.well-known/agent-skills/index.json 被誰抓走過、Link header 有沒有被解析,這些「成果層」的問題都還得靠 access log 才能回答,而我目前還沒有足夠資料。等累積一段時間的觀測再來寫一篇 follow-up 對照,應該會比分數本身有意義得多。
一個月後的 follow-up 寫在 Is It Agent Ready? 一個月後的 bot 流量實測:28 天 4,264 筆 bot 流量資料攤開,當初三條觀察有兩條成立、一條寫錯了。