Is It Agent Ready? 一個月後的 bot 流量實測
先說結論: 就這一個月的觀察下來,把網站弄成「AI 友善」,最老派的方法反而最實在。
一個月前,我把這個部落格的 agent-ready(AI 準備度)分數從 8 分刷到了 58 分。當時憑直覺做了一些設定,現在累積了 4,000 多筆數據,剛好可以回頭驗證。結果發現:當初弄得最花俏、拿最高分的那些設定,其實都只有「打分數的掃描器」在看;而我自認最得意的「專屬乾淨格式」採用率只有 2%。真正把 AI 流量帶進來的,反而是最傳統的 robots.txt 網站宣告。
打開儀表板:社群流量還是把 AI 壓著打

原本隱約覺得 AI 流量會噴發出一大塊。
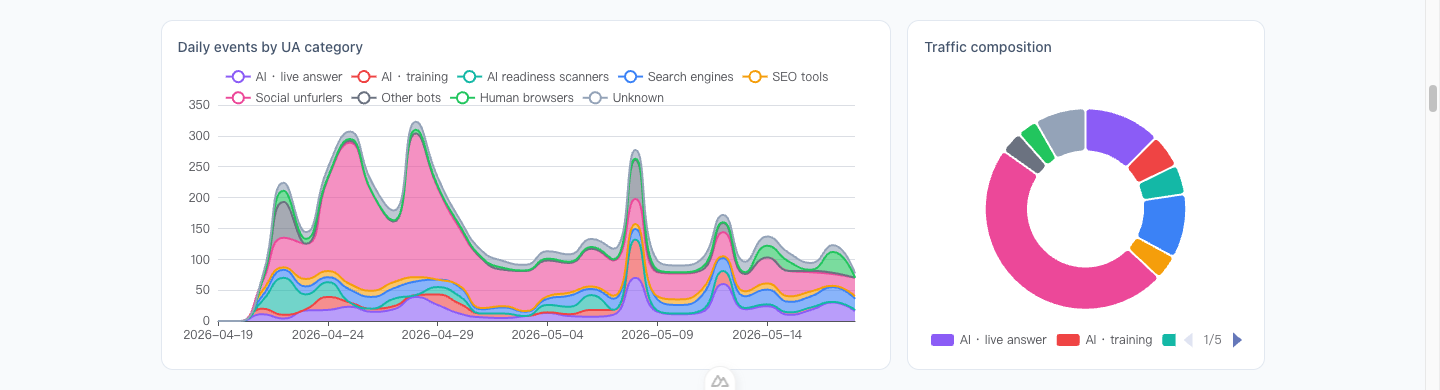
結果打開數據一看,有點意外,最大宗的還是大家在 FB 或 LINE 貼網址時,系統自動來抓「預覽圖與摘要」的社群流量,佔了將近一半(48%)。
我把 AI 機器人分成三類:「為了回答網友問題來查資料的」(像 ChatGPT)、「到處抓文章回去當訓練材料的」(像 GPTBot),以及「單純來打分數的掃描器」。這三類加起來只佔了 22%,比想像中少,而且幾乎都是 ChatGPT 跟 Perplexity 帶來的。
第一個校正: AI 流量確實起來了,但傳統的社群分享本來就是這個 blog 的命脈,AI 流量還沒大到能把它壓過去。
well-known 的 666 次請求看起來最熱鬧,拆開全是同一個東西

看數據時發現,/.well-known(一個專門放 AI 說明書的隱藏路徑)被打了 666 次,當下想說「哇,這麼受歡迎?」
結果攤開一看: 全都是「評分掃描器」跟「Chrome 瀏覽器的預載功能」在自嗨。真正的 AI(像 ChatGPT)根本沒來戳過這裡。
更好笑的是,後台留了 600 多次「找不到網頁 (404)」的錯誤紀錄。原來是掃描器瘋狂在問我當初故意不做的那些「拿高分專用端點」。這證明了原文裡的決定是對的:千萬不要光看「請求次數」就以為有市場需求,跑去硬寫那些功能,真的會被掃描器騙去白忙一場。
那個我最得意的改造,採用率 2%
這段真的是自己打臉。
上次改造中,我最得意的就是「Markdown 內容協商」,也就是說,只要 AI 告訴我「我想看乾淨的文字 (Markdown)」,我就直接給它,幫它省去解讀複雜網頁標籤 (HTML) 的麻煩。
結果這 28 天下來: AI 總共來了 500 多次,只有 10 次主動要求這個乾淨格式,採用率慘不忍睹的只有 2%。而唯一 100% 捧場用這功能的,笑死,全都是我自己拿工具在手動測試的紀錄。
技術上這機制設計得很漂亮,但現實是:現在的主流 LLM 早就習慣硬啃 HTML 了,它們根本不會主動要求乾淨格式。當初覺得「架構乾淨=會被大量採用」,實在跳太快了。當成一個長線投資可以,但當下它就是只有 2% 的採用率。
5/8 那天到底發生什麼事
平常每天流量大概 100 多次,5/8 那天突然衝到快 300 次。那天我也沒發新文章,第一反應是「哪個爬蟲壞掉了?」。
拆開 Log 一看,原來是 Perplexity、GPTBot 這些大廠的爬蟲,終於把這個 blog 排進了「定期巡邏名單」,連兩三年前的老文章都被它們翻出來重新看過一輪。
順便發現的雷達: 做完這些設定後,大概要等個「一到兩週」,大廠的生態系才會真正把你掃進去。太早看數據沒什麼意義,因為大環境還沒認識你。
原本寫最短的那條,反而帶量最大
上次文章裡我只簡單帶過 robots.txt(傳統的爬蟲規則)的設定,覺得最沒梗,結果把資料攤開看,它才是真正的大魔王。
bot_article 3,557 個事件佔全部 83%。真正帶 bot 流量的就是這層:bot 透過正常爬蟲管道進來抓 HTML 文章頁。
當初設定 robots.txt 時,我用 Content Signals 標了偏好:可以即時回答網友(ai-input=yes),但別當訓練資料(ai-train=no)。從數據看,AI 真的有在尊重這個宣告,被引用去回答問題的次數是當訓練資料的 2.2 倍(單看上一篇甚至到 5:1)。
這點直接改變了我的寫作策略:以後寫技術文,與其寫落落長的長文去拚 Google 搜尋,不如把每個段落的「結論」寫清楚,讓 AI 好摘錄。一篇文章被 ChatGPT 抓 30 次去回答網友,那種感覺跟單純被 Google 索引是完全不同的,它是真正意義上的「被即時引用」。
Is It Agent Ready? 真的 Ready 嗎
測驗工具給了我 58 分,看起來是 Ready 了。但看完這 28 天的數據,我會這樣解讀:
真正帶來 83% 流量的,是最傳統的 robots.txt 宣告,因為所有 AI 本來就懂這套老規矩。 而讓我從 8 分衝到 58 分的那些「進階 AI 改造」,真實 AI 的使用率幾乎是零。
這個分數,量測的其實是「對掃描器的友善度」;至於「AI 真的會怎麼用你的站」,它根本量不到。基礎建設我們已經鋪好了,但那些進階的玩法,目前只能等整個 AI 生態系慢慢跟上。也許半年後再回來看,那 2% 的採用率才會開始往上爬吧。