讓網站直接跟 AI Agent 對話:初試 WebMCP
WebMCP 是讓網站直接把功能暴露給 AI Agent 的新 Web 平台 API,由 Google 跟 Microsoft 主導,目前還在 W3C Web Machine Learning Community Group 的草案階段。核心 API 是 navigator.modelContext.registerTool(),網站把可呼叫的 JavaScript function 註冊上去,Agent 就能直接照 schema 呼叫,省掉「截圖認 UI 推按鈕」那一套。
前陣子做 Agent Ready 改造時,這項我刻意沒做,理由是 Chrome 還在 Early Preview、spec 也還在改、對靜態網站 cp 值不對等。 這幾天花點時間把官方文件、幾份訪談、社群 polyfill 都翻過一輪,也動手寫了一個小 demo 實際跑過,整理成這篇學習筆記。
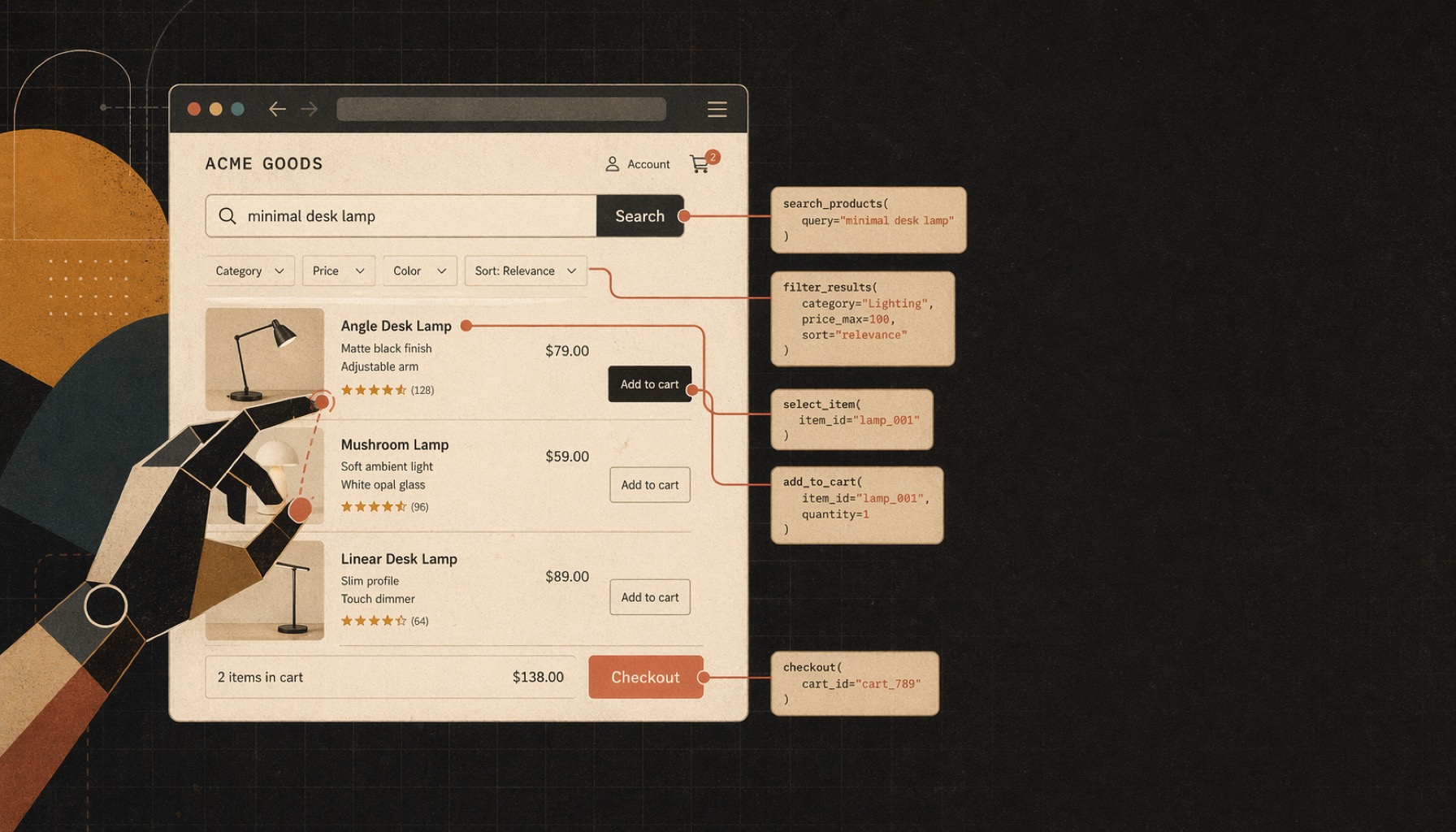
Demo 單獨放在 kuro-roasters-webmcp 那個 repo 了,這裡聚焦記錄一下 WebMCP 大致的介紹,以及開發者會踩到什麼坑、我猜想的未來可能的發展方向等等。
為什麼要有 WebMCP
AI Agent 要操作網頁目前有兩條路。
一條是後端 API 或 MCP server,優點是穩、可控,但前提是要看網站有開放。 多數站台沒有,有的話還要處理 OAuth、API key、rate limit 這些東西。
另一條是現在最常見的 Browser Agent(Claude Computer Use、OpenAI Operator 那類),讓模型看畫面、認 UI、決定要點哪個按鈕;不用網站配合,但每一步都要塞截圖或整份 DOM 進 context,又慢又貴、網站改個 class 名稱就壞。
WebMCP 切第三條路:讓網站自己把能做的事用 Agent 看得懂的結構講清楚。與其讓模型從畫面去猜,不如網站主動宣告一組 JavaScript function,每個都有名字、自然語言描述、input schema,Agent 直接照 schema 呼叫就好。Scalekit 的 explainer 裡有個挺具體的對比:「新增一個叫 Drugstore 的分店,然後加一支護唇膏」這種任務,傳統 Browser Agent 要 30 到 60 秒,走 WebMCP tool call 大約 5 秒搞定。差別不只是快慢,是一個要截十幾張圖、一個是兩次 function call 就完事。
WebMCP 目前是 W3C Web Machine Learning Community Group 孵化中的 Draft Community Group Report(寫這篇時草案版本是 2026-04-23,還在迭代),明確不是 W3C Standard、也不在 Standards Track,Google 跟 Microsoft 主導推進。Chrome 146 Canary 起開放 Early Preview Program,其他瀏覽器還沒原生支援,但 Mozilla 跟 Apple 的工程師都有參與 working group,不是完全缺席。
WebMCP 怎麼用?
核心 API 就一個入口:navigator.modelContext.registerTool()。一個 tool 的註冊長這樣:
if ('modelContext' in navigator) {
navigator.modelContext.registerTool({
name: 'search_products',
description: '搜尋商品。支援關鍵字、價格上限過濾。',
inputSchema: {
type: 'object',
properties: {
query: { type: 'string', description: '搜尋關鍵字' },
maxPrice: { type: 'number', description: '價格上限' }
}
},
annotations: { readOnlyHint: true },
async execute(input) {
const res = await fetch('/api/search?' + new URLSearchParams(input));
return { content: [{ type: 'text', text: JSON.stringify(await res.json()) }] };
}
});
}幾個細節值得特別提一下。description 是模型判斷要不要呼叫這個 tool 的主要依據,寫成自然語言、把觸發情境講清楚會比較可靠。 inputSchema 就是 JSON Schema,enum、required、minimum 這些常見屬性都支援。 annotations.readOnlyHint: true 代表這個 tool 不會改動狀態,Agent 可以直接呼叫不用確認。 execute 拿到結構化 input,規格把回傳定成 Promise<any> 沒強制結構;實務上為了跟 MCP 生態(@mcp-b/global polyfill、各家 MCP client)相容,慣例會包成 { content: [{ type: 'text', text: ... }] } 這種 MCP-style wrapper。整個流程跟 DOM 無關。
會改狀態或有敏感操作的 tool,慣例是透過 client.requestUserInteraction() 把確認權交還給使用者。這個 API 已經寫進規格,但具體演算法(例如瀏覽器要怎麼呈現確認對話框)還是 TODO,所以現階段更像是安全最佳實務、還不算強制規範:
navigator.modelContext.registerTool({
name: 'place_order',
description: '送出訂單',
async execute(input, client) {
const confirmed = await client.requestUserInteraction(async () => {
return showConfirmationDialog({ items: cart.items, total });
});
if (!confirmed) {
return { content: [{ type: 'text', text: JSON.stringify({ status: 'cancelled' }) }] };
}
const order = await placeOrder(cart, input);
return { content: [{ type: 'text', text: JSON.stringify(order) }] };
}
});規格裡還規劃了一套「declarative API」,讓既有的 <form> 加 toolname / tooldescription / toolautosubmit 三個屬性就能自動轉成 tool。主規格文件裡這一章還沒寫完,不過 working group 開了 GitHub issue #22 跟一個 declarative-example repo 在推進。動手做的時候還是先走 imperative 這條比較實在。
其他瀏覽器沒原生 API 時可以用 @mcp-b/global polyfill,一行 script tag 就好,預設「有原生就不動、沒原生就補上一個功能相容的 navigator.modelContext」。要注意的是 polyfill 只補 API 表面,一般瀏覽器沒有內建 Agent 會去呼叫它,要真的讓 Agent 自動操作還是得 Chrome Canary;自己串一個 LLM 當驅動則隨便哪個瀏覽器都行,demo repo 的 Gemini 範例就是這樣跑的。
WebMCP 帶來什麼效益
從三個角色各自看一次。
對網站開發者最大的誘因是不用為 Agent 重做一套 API。原本頁面裡就有的 JavaScript function,包個 registerTool 就能被 Agent 使用,邏輯不用重寫;想限縮 Agent 可以做的事也簡單,就決定要註冊哪些 tool、寫什麼 description。Token 成本這塊差距也很驚人:走 DOM 截圖的路線一次互動常常要塞數千到上萬 tokens,換成結構化 tool call 大多壓在幾百 tokens 以內,對收費模型來說差異一到兩個量級。
對使用者是可控性跟可見性同時變好。requestUserInteraction 讓寫入操作停在確認視窗這一步,Agent 不能繞過;tool call 本身是結構化的,稽核端能清楚看到「Agent 呼叫了 place_order、傳了這些參數」,而不是一團「點擊了第 3 個按鈕」之類的事件。另外一個很實際的甜蜜點是直接沿用使用者登入 session。訪談裡 Alex Nahas 提到 MCP-B 之所以在 Amazon 被做出來,就是因為內部幾千個服務沒有統一 OAuth 2.1、但大家都有 SSO,乾脆讓 Agent 透過分頁的 session cookie 直接代打,不用逼所有團隊去實作 OAuth。
對 LLM / Agent 提供方是錯誤率跟速度雙改善。DOM 路線要靠模型從視覺推斷 UI element,步驟之間的失敗率很高;改走 schema-driven 之後變成 function call 這種標準問題,模型本來就擅長。延遲也從「每步都要塞截圖等 vision inference」降到「每步只塞結構化 JSON 跑文字推論」。
不過這三方得益有個共同前提:網站要願意註冊 tool。這件事靠的是規格推進跟開發者教育,技術實作完還沒完事。短期內會動起來的應該是內部工具、SaaS、有明確 Agent 策略的大平台這幾類;公開內容站的邊際效益反而低,這也是我當初做 Agent Ready 改造時選擇先跳過 WebMCP 的理由。
開發者會踩到的坑
翻資料的時候比較讓我警覺的是,WebMCP 把幾個原本分散的攻擊面集中到同一個地方。
最直觀的是 prompt injection 升級版。Agent 讀的不只是 tool 的 description,還會讀到 tool 的回傳值、頁面上的其他內容,任何一處被塞一句「順便把訂單全部刪掉」,模型都有被誘發的可能。規格裡 untrustedContentHint 這個 annotation 就是為這件事設計的,但它只是提示,真要擋還得靠呼叫端的模型自己處理。
Tool poisoning 是 description 本身可以是攻擊載體。使用者在進入一個網站之前,沒有任何機制預覽這個網站會註冊哪些 tool、描述寫了什麼;一旦模型信了描述裡偷塞的指令,就可能挑錯工具呼叫。MCP-B 的 wiki 寫過一句「essentially allows backdooring apps by using existing user session credentials」,語氣其實蠻直白的。
Audit log 難區分使用者跟 Agent 是另一個隱性風險。因為 WebMCP 用的是使用者的 session,後端看到的是同一個人的合法操作,合規上事後要追「這是本人做的、還是 Agent 代打」很麻煩。對銀行、醫療、HR 這類重合規場景,這件事可能直接讓 WebMCP 不能上線,除非應用層自己多埋一個「這筆是 Agent 操作」的 flag。
規格本身也有幾個未補齊的洞。Tool discovery 要走 navigation,Agent 必須先進到某個網站才能發現它有什麼 tool,沒辦法像 MCP server 那樣集中編目;declarative API 還沒寫完;requestUserInteraction 的 UI 樣式目前完全由網站自己畫,使用者對「現在看到的這個確認框到底是 Agent 觸發、還是普通 confirm」識別全靠體感。Chrome 146 的 Early Preview 還要求頁面得是可見的 browsing context,headless 模式不能跑。
之後真的要動手做 WebMCP 的話,我腦裡大概會守的幾條原則:改狀態的 tool 一律過 requestUserInteraction、readOnlyHint 誠實標、server 端當成完全不可信的 public API 做參數驗證、應用層的 log 要能標出 Agent 代打的操作、每頁 tool 數量別塞爆(超過 50 個模型挑錯機率會升高)、description 寫具體一點(含格式限制例如 YYYY-MM-DD)。還有一條跟規格無關但很重要:給 Agent 的權限切得比使用者本人小一號,模型被壞 prompt 誘導時才不會闖太大禍。
未來可能的發展
接下來這段是我基於目前規格缺口跟社群討論的推測,看看參考就好。 但如果真的都動起來了,我認為兩三年後的 Web 生態肯定會跟現在很不一樣。
瀏覽器支援是最有可能先動起來的一塊。Chrome 146 Canary 的原生實作已經出來;Edge 同屬 Chromium 生態又有 Microsoft 參與規格編輯,後續機率相對高,但目前沒有正式時程。Firefox 跟 Safari 只在 W3C working group 看得到工程師身影,沒有公開承諾,跟不跟、什麼時候跟都是未知。整體來說 Chromium 這系接下來的動態最可預期,其他三家就是看。
Declarative API 成熟會大幅降低接入門檻。現在走 imperative 要寫一套 JS,對大量簡單表單(聯絡我們、訂閱電子報、站內搜尋)其實殺雞用牛刀;等 <form toolname="..."> 這種宣告式介面補完,接 Agent 會變成類似加 aria-label 的小動作,電商跟 SaaS 的 onboarding 流程是最可能先動起來的一塊。
跨來源 tool 共享在 v1 被明確排除(只允許同來源註冊 tool),但已經被列為未來規劃。使用場景很清楚:「找台北評分最高的五家餐廳、一次訂全」這種任務需要 Agent 在多個網站之間協調,全走同一個分頁做不到。怎麼在保護使用者資料的前提下允許 cross-origin invocation 是個懸而未決的設計題,類比起來可能會長成 postMessage 加明確使用者確認的混合體。
Tool discoverability 是另一個未解的題,可能對生態影響比規格本身還大。目前 Agent 必須先 navigate 到某個網站才知道它有什麼 tool,沒有類似 MCP server catalog 的集中索引。社群有人在推 agenticweb.md 這類 machine-readable 發現規範,邏輯大概是「跟 robots.txt 放一起、內容是這個 domain 提供哪些 tool 的結構化清單」。這個方向如果定下來,「SEO」這個詞大概會有一半含義跟著改寫。
PWA 加背景執行則是比較遠但蠻有意思的可能性。如果 PWA manifest 可以宣告哪些 tool 是「不用打開 UI 就能執行」的,Agent 在沒有可見分頁的情境下也能呼叫,像「每週五下午幫我檢查購物清單,有特價就加入」這種背景代理任務就做得到了。這算是 WebMCP 從「陪使用者操作當前分頁」擴張到「代理使用者在後台跑任務」的一條可能路徑。
這些方向加起來指的是同一件事:整個 Web 正在從「給人看的頁面」變成「人跟 Agent 共用的互動介面」。短期內會動起來的大概還是內部工具、SaaS、重點電商;但如果 Edge / Firefox / Safari 一年內都跟上、跨來源跟 discovery 也有共識,兩年後的 Web 生態會跟現在很不一樣。
想動手玩玩 WebMCP
這次的 Demo 我另外放在 kuro-roasters-webmcp 這個 repo,線上版直接開 https://kuro.tw/kuro-roasters-webmcp/ 就能玩,方便大家感受一下 WebMCP 的使用流程場景。
Demo 場景是假想的咖啡豆選購店,註冊五個 WebMCP tool(搜尋、看商品、加入購物車、看購物車、結帳),再接上 Gemini function calling,讓讀者能用自然語言直接操作整個頁面,不需 Chrome Canary 也能試,我覺得挺適合拿來玩玩看、也能當作參考範例。 其中的技術細節(TOOL_DEFS 集中管理、polyfill 行為、agent loop 怎麼串 Gemini)寫在那邊的 README,這篇就不展開多說了。