AI Agent 時代的 Vue 前端開發:從 UX 走向 AX
AI Agent 時代的前端開發,正在從 UX(User Experience)延伸到 AX(Agent Experience),也就是把網站同時設計給人類跟 AI agent 使用。對 Vue 開發者來說,這代表 component、store、route 跟 tool 之間的關係要重新整理一輪。WebMCP 這類規格只是入口;核心變化是前端工程師的工作範圍會擴大,以前歸在後端 API doc 範圍的 tool 命名、description 文案、權限邊界,正在往瀏覽器這一端推。
幾天前我寫了一篇〈讓網站直接跟 AI Agent 對話:初試 WebMCP〉,聚焦在規格本身、navigator.modelContext 怎麼用、demo 怎麼跑,想了解 WebMCP 細節的話建議先看那篇。寫完之後我意識到還有一塊沒寫:身為一個寫了多年 Vue 的前端開發者,我自己面對這波浪潮時在想什麼?Vue 的哪些結構特性剛好對得上 AX、哪些反而會變成負擔?這篇就是回答這個問題的個人筆記。
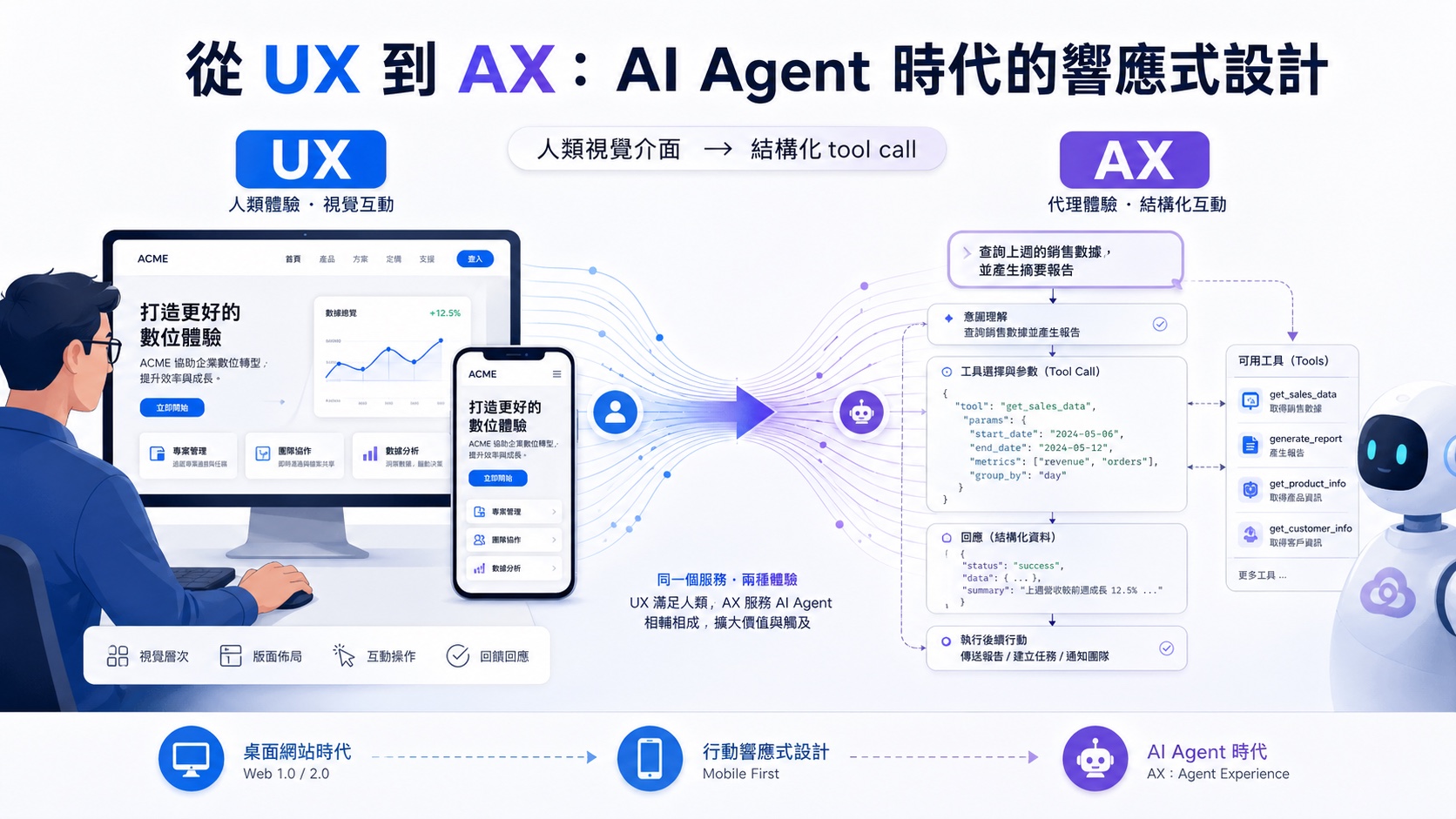
從 UX 到 AX:AI Agent 時代的響應式設計
打開這個話題,日本工程師 takoratta 在一篇文章裡把 AX 類比成「AI 時代的響應式設計」,這個比喻蠻有意思的,我讀完之後覺得確實是這樣。
回想一下 web 過去三十年的兩次大轉折。90 年代末瀏覽器戰爭打完,W3C 把 HTML / CSS / JS 標準收束起來,讓網站不用為每個瀏覽器寫一份程式碼。 2010 年前後智慧型手機普及,新的用戶端類型(行動裝置)冒出來,網站得學會同時服務不同螢幕尺寸的訪客,Responsive Web Design(RWD)變成共識。 2026 年的此刻,新的用戶端又出現了:AI agent。它沒有眼睛、不看畫面、不點按鈕,讀的是結構化的 tool schema 跟自然語言描述。 網站得再學一次「同時服務多種前提的訪客」,這次的差異在於「人類視覺 vs 結構化 tool call」。

不過這個類比也有邊界。RWD 處理的是呈現層配接,「換個 viewport 看到合適版本」就完事;AX 處理的是能力暴露跟操作邊界,「agent 能呼叫什麼、傳什麼、後果是什麼」。所以 AX 的安全性、權限模型、稽核這些東西會比 RWD 更核心,光把 RWD 經驗搬過來不夠用。
換個角度看,網站的訪客正在分化成三種:人類、傳統 crawler(搜尋引擎、AI 訓練爬蟲)、即時操作的 agent。前兩種都還是「讀」資訊,差別只在誰來消化;第三種是「操作」資訊,讀完之後會直接呼叫 tool 改變狀態。AX 真正想處理的是這第三種訪客,他們對網站的期待已經超過「給我可讀的 HTML」這層,需要的是一份可呼叫的能力清單。
這就是 AX 想處理的問題。
AX 是什麼
AX 是 Agent Experience 的縮寫,由 Netlify 共同創辦人 Matt Biilmann 提出,agentexperience.ax 上有官方定義:「AI agent 在跟產品、平台或系統互動時得到的整體體驗」。它跟 UX(User Experience)、DX(Developer Experience)是同一個概念家族,差別只在受眾從人類使用者、開發者擴大到了 agent。
套到網站場景,AX 講的是當 agent(語言模型、瀏覽器內建的 AI、自動化腳本)成為訪客時,我們為這類非人類用戶端設計的操作體驗。過去網站的預設訪客只有一種,有眼睛、會操作滑鼠跟觸控的人類,所有資訊都塞在渲染完的視覺層;agent 想介入只能靠截圖猜按鈕位置或爬 DOM 反推語意,品質一直很差。WebMCP 跟 NLWeb 這類規格冒出來,等於是讓網站第一次能對 agent 說「這頁有哪些操作、輸入是什麼、後果是什麼」。AX 在描述的就是這種對話品質。
要先 caveat 一下,這篇主要從 WebMCP 角度切入 AX,但 AX 本身是更廣的概念,跟 NLWeb、Browser Agent、未來的其他 agent-facing API 都有交集。WebMCP 只是目前最具體可動手的一條路徑。
跟 UX 對照看比較容易抓到邊界。UX 想的是視覺層級、互動回饋、頁面節奏這類人眼在意的事;AX 想的是 tool 命名要不要白話、description 文案夠不夠精準讓 LLM 一次選對、錯誤訊息有沒有告訴 agent「為什麼錯、要怎麼修」、哪些動作要強制人類二次確認。失敗模式也不一樣,UX 失敗是使用者點不到、找不到;AX 失敗是 agent 選錯工具、塞錯參數、無腦重試把 server 打掛。
| 維度 | UX | AX |
|---|---|---|
| 用戶端 | 人類 | agent / LLM |
| 主要輸入 | 視覺、滑鼠、觸控 | 結構化 tool schema、自然語言描述 |
| 失敗模式 | 點不到、看不懂 | 選錯工具、參數不符、誤觸高風險動作 |
| 設計重點 | 視覺層級、互動回饋、文案語氣 | tool 命名、description 文案、權限邊界、agent 友善的錯誤訊息 |
| 維運債 | UI 跟設計稿 drift | UI 跟 tool definition drift |
AX 跟 SEO / a11y / semantic HTML 的關係
AX 容易被混進現有的 SEO、accessibility、semantic HTML 這幾條既有討論裡。我自己一開始也想過「這不就是 a11y 換個名詞嗎」,後來想清楚三者其實在處理不同層面的問題。SEO 處理「內容能不能被搜尋引擎理解、進 index、出現在搜尋結果」;accessibility 處理「人類使用者(特別是有輔助科技需求的)能不能順利操作網站」;AX 處理「agent 能不能搞清楚這個網站允許我做哪些事、要丟什麼參數、做了會發生什麼後果」。
三者會共享一些基礎,例如語意化 HTML、清楚的狀態、穩定的資訊結構。但 AX 多出一層 capability design:網站除了被讀,還可以被呼叫。這層是 SEO 跟 a11y 都沒在處理的。
AX 把哪些工作推到前端
AX 對前端工程師最直接的影響,是工作邊界正在重畫。
過去前端跟後端有一條相對清楚的分工線:後端負責 API 設計、命名、文案、權限模型;前端負責把資料拿來渲染、處理互動。tool 命名好不好、description 文案精不精確、權限邊界畫在哪,這些是 API doc 的事,前端讀文件來用就好。
WebMCP 把這條線往前端拉了。至少從目前 draft API 的形態來看,tool 註冊發生在瀏覽器,跟著 component 生命週期走,跟 UI 文案共用同一份 i18n,輸入 schema 通常借用前端已有的 form validation library(Zod、VeeValidate)。換句話說,以前你寫一份 API spec 給後端,他幫你做一支 endpoint 出來;現在你直接在 Vue component 裡 registerTool,description 文案就是你寫,輸入 schema 就是你的 form schema,errors 訊息就是你 UI 顯示的那份。
工作量轉移之外,連帶把幾個過去看似後端責任的東西,實質變成前端設計問題:
Tool 命名跟 description 文案 LLM 選工具靠的就是這兩個欄位,寫得好可以一次選對,寫不好就會誤呼叫或無腦重試。這是寫作問題,需要思考的是:讀者(模型)在什麼情境會看到這段文字、它需要什麼資訊才能做正確判斷。前端工程師寫 UX 文案累積的肌肉記憶其實很接近,只是受眾換了。
權限邊界 哪些 tool 可以給 agent 自由呼叫、哪些必須走 requestUserInteraction、哪些角色才看得到、跨頁的時候要不要回收,這些以前是後端 authorization 在管的事,現在會散落在 component 跟 store 裡。Vue 開發者過去靠 router guard 跟 provide/inject 處理 UI 層權限,同一套機制現在要延伸到 tool 層。
錯誤訊息的 agent 版本 給人類看的錯誤訊息可以是「請稍後再試」,給 agent 看必須是結構化、可動作的:為什麼錯、缺什麼參數、要怎麼修、能不能重試。前端要學會同一個錯誤寫兩份文案,一份給人、一份給 agent。
UI 跟 tool definition 的 drift 問題
這幾個工作推到前端之後,會浮現一個維運核心問題:UI 跟 tool definition 各改各的。
我自己第一次體會到嚴重性,是試著把 demo 裡的搜尋欄位改了一個欄位名,UI 沒事(因為是表單渲染),但對應的 search_products tool 的 inputSchema 我忘了改,agent 還在用舊欄位名呼叫。Browser 端不會報錯,只回 200 加空陣列,模型以為「沒搜到」就再試一次,變成失敗迴圈。
這種 drift 在純後端 API 時代不太發生,因為 API 跟 UI 之間有 contract,改 API 一定要改 client,IDE 會跳紅字。但 WebMCP 的 tool 定義跟 UI 都在前端,沒有編譯時期的強制連動,改 UI 忘記改 tool 是最容易發生的事。
這是 AX 帶給前端工程師最具體的維運債,也是接下來看 Vue 結構優勢的時候,最值得拿來檢驗各種設計選擇的標準:這個寫法會讓 drift 變嚴重,還是減輕?
為什麼我認為 Vue.js 適合 AX?
走完 AX 的概念框架,接下來想拉回到具體技術棧上。我自己寫了多年 Vue,在實際試做 WebMCP demo 的時候,有幾個瞬間意識到一件事:AX 場景需要的東西,Vue 的 mental model 早就準備好了。以下整理五個契合點。
Reactivity 跟 tool 狀態天生匹配
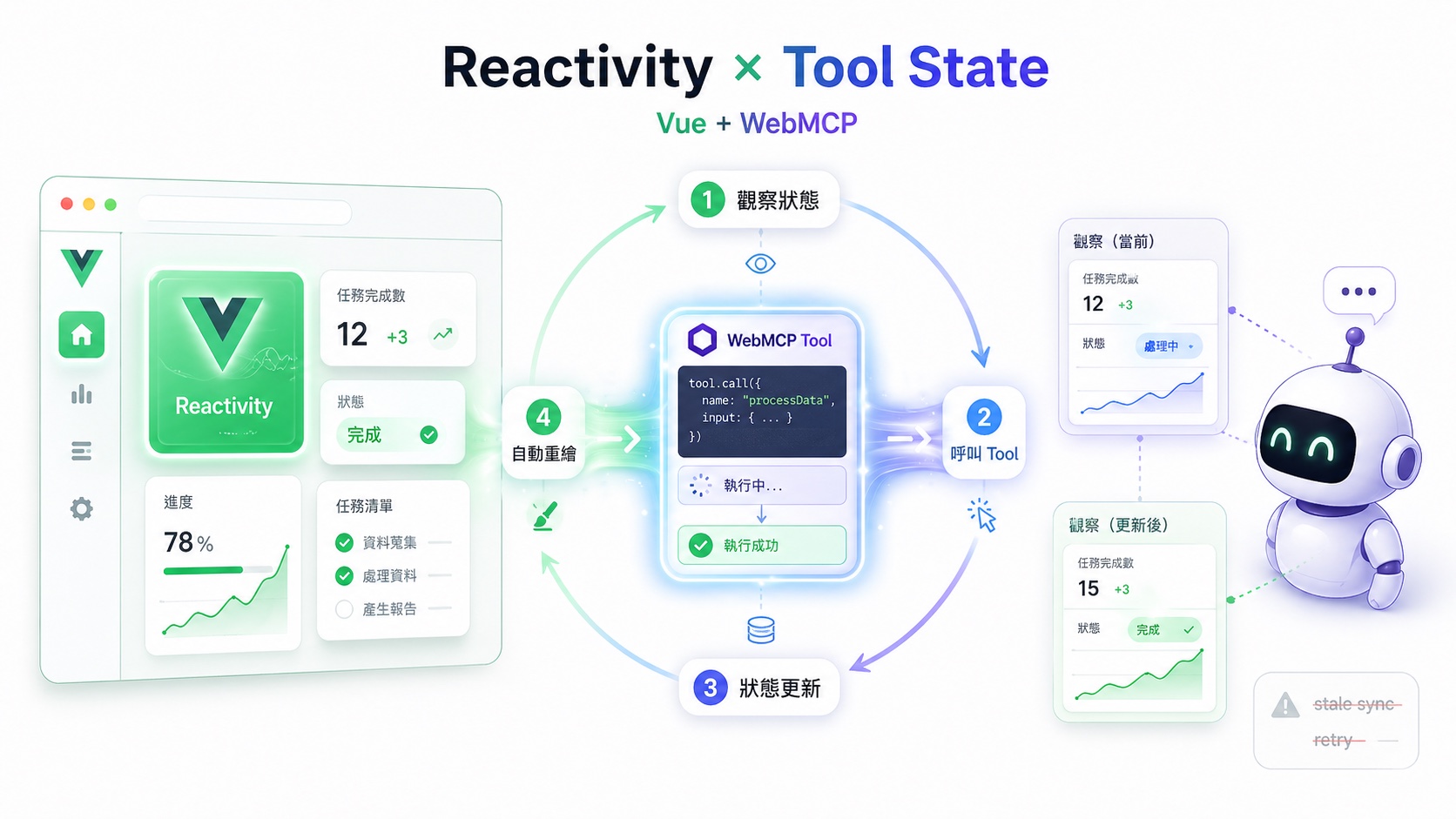
WebMCP 最核心的循環是:agent 觀察狀態 → 呼叫 tool → 觀察狀態變化。Vue 的 reactivity 系統把這件事做到極致,tool 內部改一個 ref 或 store,UI 自動 re-render,agent 下一次讀畫面就看到新狀態。
我自己寫 React 寫到類似場景時,常會在 hook dependency、closure freshness、memoization 邊界這些地方多花力氣;Vue 的 ref / computed / store 模型比較貼近「狀態變了,UI 跟 agent 的觀察結果會一起更新」這種直覺,這層在 Vue 幾乎零成本。對 AX 場景特別重要,因為 agent 每次呼叫 tool 預期的是「執行完狀態就該變」,如果中間有同步問題,agent 會以為操作失敗去重試。
Pinia action 是 tool wrapper 的好入口
Vue.js 開發生態圈的 Pinia action 在形狀上很接近一個 tool:具名、集中副作用、可回傳結果。 把現有的 store action 用 registerTool 包一層,agent 立刻就能呼叫,而且因為 action 本來就是 component 在用的,等於人類使用者跟 agent 共用同一份業務邏輯,不會分裂。
一個 Pinia action 要真的變成 production-ready 的 tool,我自己評估至少要補五件事:
- runtime input schema(Zod 或 valibot,光靠 TypeScript 型別不夠,因為 agent 傳的是 JSON)
- agent-readable description(寫給 LLM 看的自然語言文案,跟給 IDE intellisense 看的 JSDoc 是兩回事)
- 權限檢查(這個 action 該不該開放給 agent、目前角色能不能用)
- agent-friendly 錯誤語意(回傳結構化原因,不只是 throw)
- audit log(這次呼叫是 agent 還是人類觸發、傳了什麼參數)
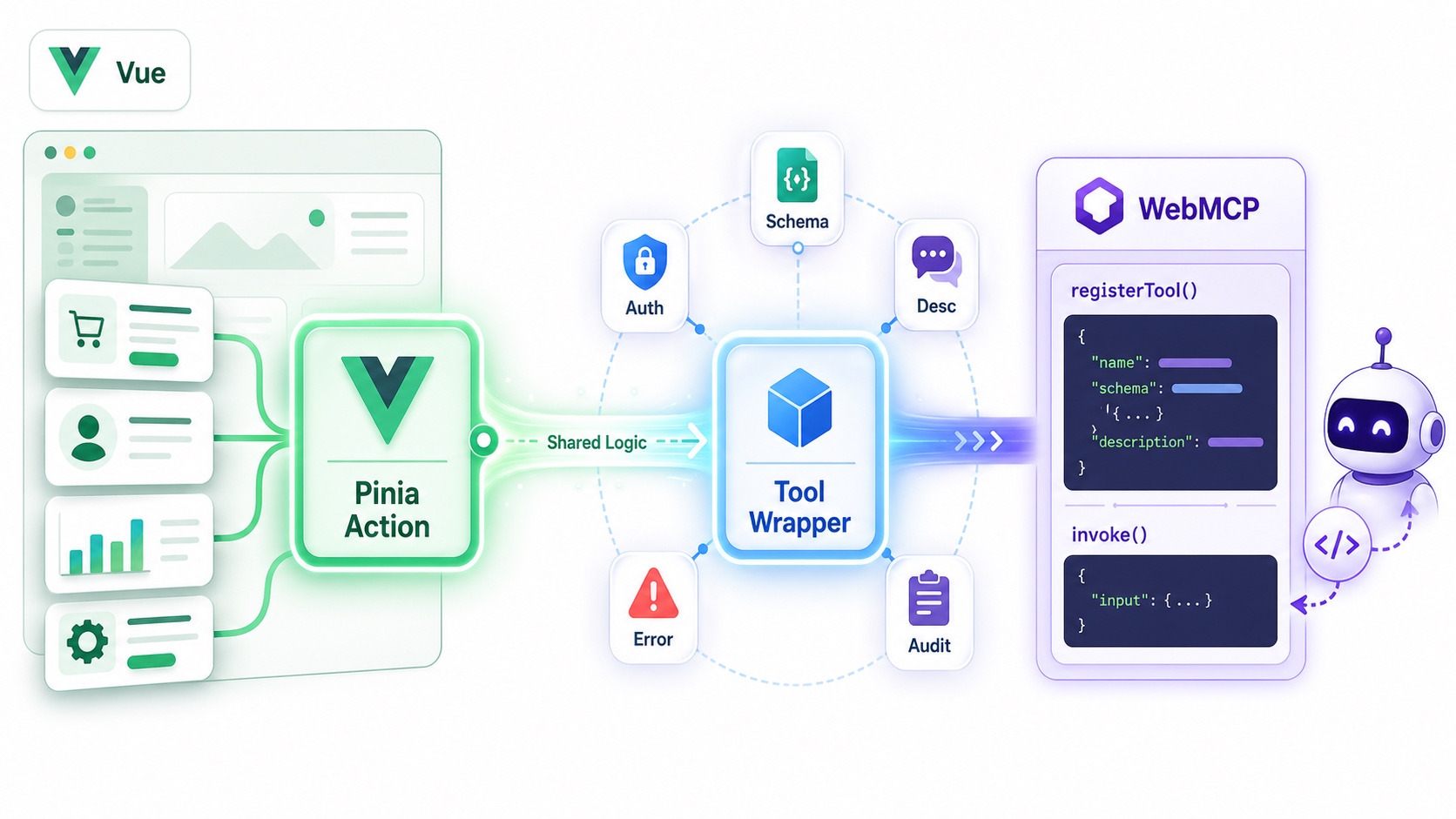
寫一個 defineMcpTool() helper 從 store 自動註冊只是起點,真正的工作量在補上面這五件事。 但起點接近終點這件事仍是 Vue 的優勢,React 那邊把分散在 reducer / hook / context 的副作用收斂成 tool 起手式更遠。
Composition API 生命週期 = tool scope
onMounted 註冊、onBeforeUnmount 取消註冊,這個 pattern 把 tool 的可用範圍跟 component 生命週期綁在一起,做出來的效果是:agent 看到的工具集會跟著使用者導航自然變化。
舉個例子,結帳頁才出現的 applyCoupon tool,在使用者離開結帳頁的瞬間就消失。對 LLM 而言這是大幅降噪,看到 5 個情境相關 tool 比看到 50 個全站 tool 選擇品質好太多。Composition API 的 setup 函式天然就是執行這種註冊邏輯的地方,寫起來像呼吸一樣自然。
SFC 讓 tool 定義跟 UI 住在一起,抑制 drift
回到上一節說的 drift 問題。SFC 是 Vue 對抗這個問題的天然優勢:tool 定義可以寫在控制它的 component 旁邊,改 UI 的時候很難不看到 tool 定義也得改。
對比一下集中註冊 pattern:有的設計是把所有 tool 集中在一個 tools.ts 或 mcp-server.ts 裡定義,改 UI 的人根本不會開啟那個檔案,drift 機率最大化。SFC 把兩者放在同一個檔案的兩個 <script> 段,physical proximity 帶來的 cognitive coupling 是零成本的維運債抵抗力。
這當然不是銀彈,跨頁流程的 tool 還是得放 store 或全域 composable,不能塞 component。但對「這頁能做的事」這類常見場景,SFC 結構是最佳解。
vue-router 的 meta + Pinia 補完權限與 context
最後一塊是路由跟 context。WebMCP tool 常常需要知道目前的登入狀態、feature flag、使用者角色,如果每個 tool 自己拉這些資訊會很重。
Vue 的標準作法裡,這類共享 context 通常已經住在 Pinia store(useAuthStore、useFeatureFlagStore),useMcpTool 直接 import 過來用即可。vue-router 則補上「路由級」這層:用 route.meta.requiresAdmin 標註權限門檻,讓 tool 註冊邏輯讀 meta 決定要不要曝露 tool 給 agent。
具體配合方式長這樣。先在 vue-router 的 routes 定義裡標權限:
// router/routes.ts
import type { RouteRecordRaw } from 'vue-router'
export const routes: RouteRecordRaw[] = [
{
path: '/admin/users',
component: () => import('@/views/admin/UserList.vue'),
meta: { requiresAdmin: true }
}
// 其他路由 ...
]接著在 admin 頁面 component 的 <script setup lang="ts"> 內,讀 route.meta 跟 Pinia auth store 一起判斷,條件不符就乾脆不呼叫 useMcpTool,agent 自然看不到這個 tool:
// components/admin/UserActions.vue 的 <script setup lang="ts"> 內容
import { useRoute } from 'vue-router'
import { useAuthStore } from '@/stores/auth'
import { useMcpTool } from '@/composables/useMcpTool'
const route = useRoute()
const auth = useAuthStore()
// 雙重檢查:路由標 requiresAdmin + 當前角色是 admin
if (route.meta.requiresAdmin && auth.role === 'admin') {
useMcpTool({
name: 'delete_user',
description: '刪除指定使用者帳號(永久動作,僅 admin 可呼叫)',
inputSchema: {
type: 'object',
properties: {
userId: { type: 'string', description: '要刪除的使用者 ID' }
},
required: ['userId']
},
async execute(input: { userId: string }) {
const res = await fetch(`/api/admin/users/${input.userId}`, {
method: 'DELETE'
})
return {
content: [{ type: 'text', text: JSON.stringify(await res.json()) }]
}
}
})
}整套機制都在 Vue 既有 mental model 之內,不用引入額外的依賴注入機制。Server 端當然還要再驗一次權限,client-side 條件式註冊只是降低 tool 暴露面,不能當成最終守線。
Vue 開發者的最小切入點
理論講完,實作上我自己會建議的最小切入路徑長這樣。
第一步:從 read-only tool 開始
不要一開始就把寫入類 tool 開出來。先選 3 到 5 個 read-only 的查詢類 action(搜尋、篩選、看詳情、看清單),包成 tool 觀察 agent 行為。這個階段的目標只有兩個:
- 觀察 LLM 怎麼選擇你的 tool:description 寫得夠不夠精準?常常選錯的話文案要怎麼改?
- 觀察 agent 的呼叫頻率跟錯誤模式:會不會無腦重試?errors 訊息夠不夠 agent 友善?
跑兩三天之後再決定要不要開寫入類 tool。這比一次全開安全很多,也讓你有時間建立 audit log 跟監控。
第二步:Pinia action 包成 tool 的範本
我自己用的範本大概長這樣(假設用 Pinia + Zod,比舊文 demo 多了 store 整合跟 schema 重用):
先在 stores/products.ts 集中業務邏輯:
// stores/products.ts
import { defineStore } from 'pinia'
import { ref } from 'vue'
interface Product { id: string; name: string; price: number }
export const useProductStore = defineStore('products', () => {
const items = ref<Product[]>([])
async function searchProducts(input: { query: string; maxPrice?: number }) {
const params = new URLSearchParams()
params.set('query', input.query)
if (input.maxPrice !== undefined) params.set('maxPrice', String(input.maxPrice))
const res = await fetch('/api/search?' + params.toString())
items.value = await res.json()
return items.value
}
return { items, searchProducts }
})接著抽一個極薄的 composable 處理 WebMCP 註冊與生命週期:
// composables/useMcpTool.ts
import { onMounted } from 'vue'
type McpToolDefinition = {
name: string
description: string
inputSchema: unknown
annotations?: Record<string, unknown>
execute: (input: unknown) => Promise<{
content: Array<{ type: 'text'; text: string }>
}>
}
export function useMcpTool(definition: McpToolDefinition) {
onMounted(() => {
if (typeof navigator === 'undefined') return
if (!('modelContext' in navigator)) return
;(navigator as any).modelContext.registerTool(definition)
})
// 規格目前還沒明確的 unregister API,現階段先把註冊綁在 component lifecycle 上,真正的 dispose 等規格補完再接
}最後在 component 的 <script setup lang="ts"> 內把 store action 包成 tool,schema 重用同一份 Zod 定義:
// components/ProductSearch.vue 的 <script setup lang="ts"> 內容
import { z } from 'zod'
import { zodToJsonSchema } from 'zod-to-json-schema'
import { useMcpTool } from '@/composables/useMcpTool'
import { useProductStore } from '@/stores/products'
const store = useProductStore()
const searchInputSchema = z.object({
query: z.string().describe('搜尋關鍵字'),
maxPrice: z.number().optional().describe('價格上限,單位 TWD')
})
useMcpTool({
name: 'search_products',
description: '搜尋咖啡豆商品。支援關鍵字、價格上限過濾。回傳符合條件的商品列表。',
inputSchema: zodToJsonSchema(searchInputSchema),
annotations: { readOnlyHint: true },
async execute(input: unknown) {
const parsed = searchInputSchema.parse(input)
const result = await store.searchProducts(parsed)
return { content: [{ type: 'text', text: JSON.stringify(result) }] }
}
})幾個重點。searchInputSchema 這個 Zod schema 同時餵給 tool 的 inputSchema 跟 execute 的 runtime parse,確保 agent 傳什麼進來都先過一次驗證。description 寫得比一般 JSDoc 仔細,因為 LLM 沒有其他資訊可參考。useMcpTool 是極薄的 wrapper,只處理特性偵測跟生命週期,不做任何業務假設。
第三步:動態 scope tool,跟著畫面或路由走
不要把所有 tool 在 app 啟動時一次註冊完。用 component 生命週期或路由切換做動態 scope:
- 結帳頁才註冊
apply_coupon、place_order - 商品列表頁才註冊
add_to_cart - 後台才註冊
delete_user、reset_password
這樣 agent 在任何時刻看到的 tool 集合都跟使用者當下情境對齊,選擇品質好很多。
第四步:別太早抽 useMcp() 框架層
WebMCP 還在 Community Group draft,API 形狀、permission model、最佳實踐都可能變動。太早把一套 useMcpComposable() 抽成內部框架,相當於把不穩定 proposal 凍結進 API,之後 spec 改一下整個 codebase 都要連動。
我的判斷標準是「同一段 composable 在第三個專案複製貼上」才考慮抽出來,而且只抽薄框架層(SSR 守衛、生命週期),業務邏輯留 example/recipe,不要進 core。
Vue 場景的劣勢與務實決策
寫到這裡都在講 Vue 的好,接下來換一段誠實的反面。Vue 不是萬能,有些 AX 場景反而是 Vue 的短處。
SSR / hydration 邊界要嚴格守
這個是 Nuxt / VitePress 場景必踩的雷。WebMCP 註冊邏輯如果不小心放在 module top-level、plugin 初始化、setup 同步階段、或 Nuxt 的 universal plugin,server 端執行會直接炸,因為 navigator 不存在。
守則只有一條:註冊邏輯嚴格放在 client-only lifecycle。具體做法是 onMounted 內部、if (import.meta.env.SSR) return 守衛、Nuxt 的 .client.ts plugin 命名。只要嚴守 client-only,SSR 風險可控,危險的是不小心放到 universal scope。
Tool boundary 的資料正規化是新手坑
WebMCP 的 tool execute 函式,輸入輸出原則上只該傳 plain JSON-compatible data。但 Vue component 裡的 ref / reactive / computed 是 proxy,如果直接把 reactive 物件回傳給 agent,可能會出現幾種問題:
- proxy identity 跟 raw identity 不同,跨邊界比對會錯
- 巢狀 ref / computed 被序列化成意外形狀
- class instance、Date、Map、Set、File、Blob、function 跨邊界本來就不安全
- tool schema 預期 plain JSON,proxy 物件不一定符合
解法是必要時用 toRaw()、unref()、schema parse、structuredClone() 做正規化。Code review 應該把這個列為重點檢查項,因為一旦寫錯,測試在瀏覽器裡跑常常看不出問題,只有 agent 端的回應品質會慢慢崩壞。
Component 邊界 ≠ tool 邊界
跨頁流程是 Vue + WebMCP 最不順手的地方。例如電商結帳橫跨「購物車 → 確認地址 → 選付款 → 完成」三四頁,這條 flow 上的 tool 不能放任何單一 component,因為 component 一卸載 tool 就消失。
這時候 tool 必須放 store 或全域 composable,意味著「tool 跟 UI 住在一起」的好處在跨流程場景失效。一個專案會混用兩種風格(component-scoped 跟 store-scoped),一致性會下降,新進工程師需要學會分辨「什麼時候放哪」。
我目前能想到比較順的解法有三條,不能說完美,但都比「亂放」好:
(a) Layout component 當 tool scope 跨頁 flow 通常會有共用 layout(例如 <CheckoutLayout> 包住結帳的四頁),把 flow 級 tool 的 useMcpTool() 呼叫放在 layout 的 setup 函式裡,讓 layout 的生命週期當 tool scope。使用者進入 /checkout/* 路由就註冊,離開整個 layout 才卸載。這個寫法保留了「tool 跟 UI 住在一起」的好處,又解決 component 一頁一卸載的問題。
(b) 流程級 composable 顯式管理 scope 如果 flow 由多個獨立 component 組合,沒有共用容器,可以寫一個 flow-level composable,由 flow 入口呼叫、出口呼叫 dispose:
// flows/checkout/useCheckoutFlowTools.ts
export function useCheckoutFlowTools() {
if (typeof navigator === 'undefined' || !('modelContext' in navigator)) {
return () => {}
}
const ctx = (navigator as any).modelContext
ctx.registerTool({ name: 'apply_coupon', /* ... */ })
ctx.registerTool({ name: 'place_order', /* ... */ })
// flow 退出時呼叫,進行清理
return () => {
// WebMCP unregister API 規格成熟後接上
}
}把 register / dispose 兩端寫在同一個檔案,code review 比塞在 store 裡更看得出 scope 範圍。要 caveat 的是 WebMCP 規格目前沒明確的 unregister API,dispose 函式現階段比較像佔位,實務上靠 page 卸載清掉註冊狀態,等規格補完才能真正做 cross-flow 清理。
(c) vue-router navigation guard 最後一條走路由:beforeEach 進入 flow 時呼叫 register,afterEach 偵測離開時呼叫 dispose。邏輯集中在 router 設定檔,所有 flow 級 tool 都在同一個地方管理;缺點是跟 component 距離拉遠,drift 風險回來了。
實務上我會優先試 (a),layout-driven 既符合 Vue 慣例、又抑制 drift;(b) 留給沒共用 layout 但邊界仍清楚的場景;(c) 通常是 codebase 已經習慣「集中註冊」風格才用。團隊裡訂一條清楚規則(例如「flow 級 tool 一律走 layout,store 只放純資料、不放 tool 註冊」),新進工程師才不會混亂。
Bundle size 對 agent-first 場景不划算
Vue 3 + Pinia + Router + WebMCP runtime 加起來大致落在數十 KB gzip 等級(實際數字以你的 bundle analyzer 為準,受 tree-shaking 跟用量影響)。對一般 SPA 這個 size 沒問題,但對 agent-first 場景(API doc、純內部工具、純 agent endpoint)就完全不划算。
agent 不需要 reactivity、不需要 component 樹、不需要 router,給它一套完整 reactive SPA stack 等於 99% 的能力它用不到。這類場景用原生 JS 寫一支百來行的 WebMCP 註冊腳本反而乾淨。
Devtools 跨兩個世界
Vue Devtools 看不到 MCP 呼叫,MCP Inspector 看不到 reactivity 訊號。沒有單一介面同時看到「tool → action → state → re-render」這條鏈路,debug 的時候要自己埋 trace,在兩個 devtools 之間切換對照。這個目前無解,只能等生態成熟。
決策樹
整理一下什麼場景值得用 Vue 做 WebMCP、什麼不值得:
| 情境 | 建議 |
|---|---|
| 已是 Vue + 重 form/state(後台、CMS、SaaS dashboard) | 優勢遠大於劣勢,值得做 |
| 內容驅動、SSR 為主、互動少(部落格、行銷頁、文件站) | Read-only tool 用原生 JS 註冊更乾淨 |
| 全新專案還在選技術棧 | 不要為了 WebMCP 選 Vue。技術棧由團隊熟悉度跟主要使用者決定,agent 整合放第二順位 |
順帶補一個常見誤解。對純內容站(部落格、行銷頁、文件站)而言,先把 semantic HTML、結構化資料(Schema.org)、清楚的標題層級整理乾淨,對 AI crawler 跟 Browser Agent 的幫助比直接做 WebMCP 還大。WebMCP 走的是 navigator.modelContext.registerTool(),繞過 DOM;做語意化 HTML 服務的是另一群讀 DOM 的 AI 訪客(搜尋爬蟲、Computer Use 那類)。沒做 WebMCP 不等於對 AI 擺爛,看你想接的是哪種訪客。
動工前該寫的兩份清單
最後是我覺得對成熟網站引入 WebMCP 最關鍵的一個動作:在 sprint kickoff 前,跟團隊一起花一個下午寫兩份清單。這兩份清單會直接決定後續排程的優先順序,也避免做著做著,一個寫入類 tool 偷偷溜上 production。
清單一:現有 API 哪些可安全包成 tool
把站上所有 API endpoint 列出來,對每一支問三個問題:
| 檢查項 | 問題 | 通過標準 |
|---|---|---|
| 可呼叫性 | 這支 API 可不可以無人類確認直接呼叫? | 純查詢、無副作用 → 通過 |
| Schema 完備性 | 輸入是不是已經有清楚的 schema? | 已有 Zod / OpenAPI / JSON Schema 定義 → 通過 |
| 回傳結構性 | 回傳格式是不是 agent 友善? | 結構化 JSON、錯誤碼可區分 → 通過 |
三題都通過的優先做,可以包成 read-only tool 馬上上線;通過兩題的次之,補一補就能上;只通過一題或全敗的最後做,可能要先改 API 才包得起來。這個分級會直接餵給 sprint planning 的 backlog,避免「想到什麼就先做什麼」的隨機開發節奏。
清單二:哪些操作絕對不開放給 agent
這份清單可能比清單一還重要。常見的紅線項目大概可以分成五類:
- 不可逆動作:刪除使用者、刪除訂單、清空購物車、移除上傳檔案
- 金流相關:變更付款資訊、轉帳、退款核可、修改訂閱方案
- 權限變更:升降級角色、加減團隊成員、產生 API key、變更 SSO 設定
- 對外通訊:寄客訴信、發出工單、推播通知、群發 email
- 法規敏感:個資存取、醫療紀錄、未成年資訊、跨境資料傳輸
這些動作就算上 requestUserInteraction 二次確認都未必夠,因為 agent 可以在前面的對話誘導使用者「等下會跳出確認框,按確認就好」。 安全做法是直接從 tool 列表排除,只留人類走 UI,agent 想做就主動跟使用者說「這個我不能幫你,請你自己操作」。
兩份清單怎麼用
寫完之後,把清單一的優先順序帶進 sprint planning,把清單二的紅線寫進 code review checklist(PR 加 tool 之前,reviewer 先檢查 tool 名稱有沒有撞到紅線)。 每個 sprint 結束更新一次:新的 API 上線就追加到清單一,業務變化就調整紅線範圍。清單寫完歸檔不更新,等於沒寫。
後記
寫到這裡,我自己對 AX 這件事的感覺是,它不會在一兩個月內顛覆前端工作,但會在一兩年內慢慢滲透進每個 Vue 開發者的日常。Pinia action 多寫兩行 description、表單多走一次 Zod schema、router meta 多塞一個 agentAccessible flag,這些小動作累積起來,就是這個世代前端工程師的新基本功。
身為 Vue 的開發者,我認為 Vue.js 在這場轉型裡的位置是有利的。 Vue reactivity 對「state 同時餵 UI 跟 agent」近乎零成本,Pinia 對 tool 註冊起手式接近終點,SFC 對 drift 抑制天然有效。 這些都是 mental model 上的契合,不是套件數量的堆疊。
寫這篇的同時,好友 Paul Li 拿 Yahoo!拍賣的頁面做了一個 WebMCP demo。他註冊了兩個 tool,demo 影片裡示範 agent 辨識「找預算內的 Nintendo Switch 2」這類使用者意圖時,會直接呼叫對應 tool 跳到最精準的搜尋結果頁,跳過視覺辨識跟 DOM 解析那套。
雖然這還只是 demo 不是上線版本,但能在大型電商規模的頁面上跑出兩個 tool 的差異就已經很有意義,至少能說明動手實驗的成本沒大家想像中高。
至於 WebMCP 規格本身會不會像 Schema.org / microformats 那樣熱鬧開場、最後普及不如預期?老實說我也不知道。 但 Vue.js 的開發生態圈上,做 AX 的邊際成本不高、回頭成本也不高,先從 read-only tool 開始試水溫,觀察一陣子再加碼,我覺得是合理的賭注策略。